For SWET4 (Swedish Workshop on Exploratory Testing #4) I was prepared to talk about modelling information flow in testing and how I had used it. I’d called the topic “Modeling: Information-driven Testing VS Activity and Artifact-driven Testing”.
The drive of the proposed talk/discussion was about using models to illustrate traps associated with many projects - especially large projects, projects with large product bases or legacy systems. This comprised of two illustrative models.
The first:
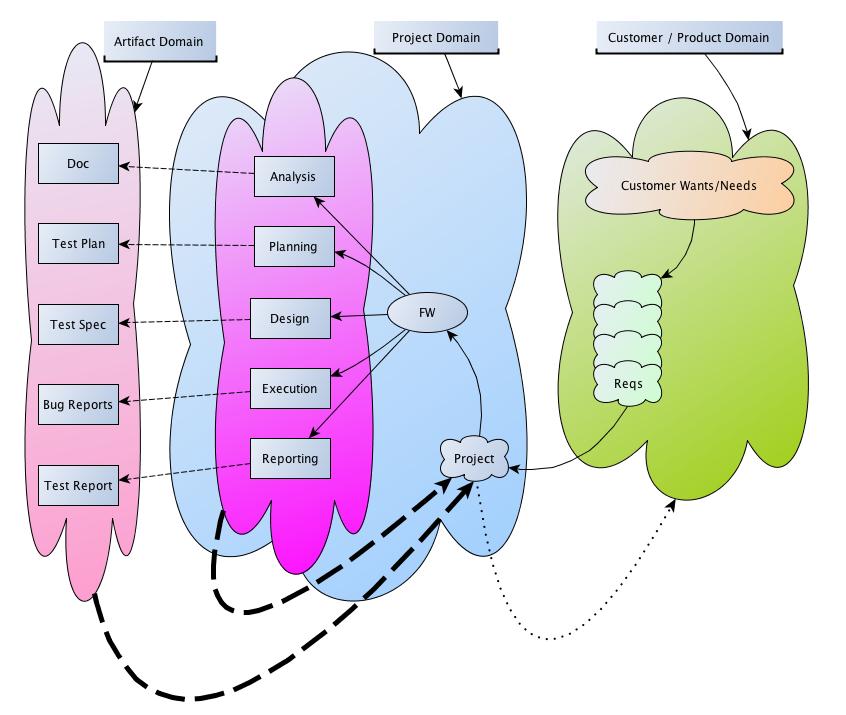
Model #1
In the diagram notice the flow of customer requirements that devolve into a project which, from a testing perspective, turns into some form of analysis, design, execution and reporting. Typically there may be some artifact from these activities. These typically produce part of the “answers” that the project and product are looking for (some of these “answers” may come in non-artifact form also, eg verbal reporting).
I assert that this is the view of the non-tester in many situations - whether from a project or product (owner) perspective. This is no bad thing in itself, but... After a number of repetitions it can happen that this is /the/ model for delivering on requirements -> that a project is set up we turn the handle with a number of given activities, produce a number of given artifacts and then deliver to the customer.
Some problems with this:
- The focus is on the containers - the activities and artifacts - rather than the contents. The contents (or content needs) should dictate the needed activities and artifacts, not the other way around*.
- The traps associated with Taylorism - splitting activities into unitary items (to optimize and measure) becomes a goal in itself. These look like targets, but can lead to local optimizations and process gaming (skewing) due to measurement goals.
- The model is used as an exemplar as it has succeeded with a (several) project(s) already.
- Familiarity with the model (system) is thought of as a closed system - meaning it’s processes and flows are defined and known to the extent that they are considered (by their practitioners) as complete.
- The previous two points contribute to the model becoming a best practice.
So, is this model wrong?
It depends... on how the model is used.
The activities and artifacts are not wrong in themselves. I am not saying these artifacts
cannot be produced or that these activities cannot be done.
The usage of it can be illustrative - or informative versus normative - to show what a “general” flow might look like. But I think there are several alternatives. It’s important to start at the needs end of the equation and build components that are congruent with those needs.
Mapping Information Flow
The second model:
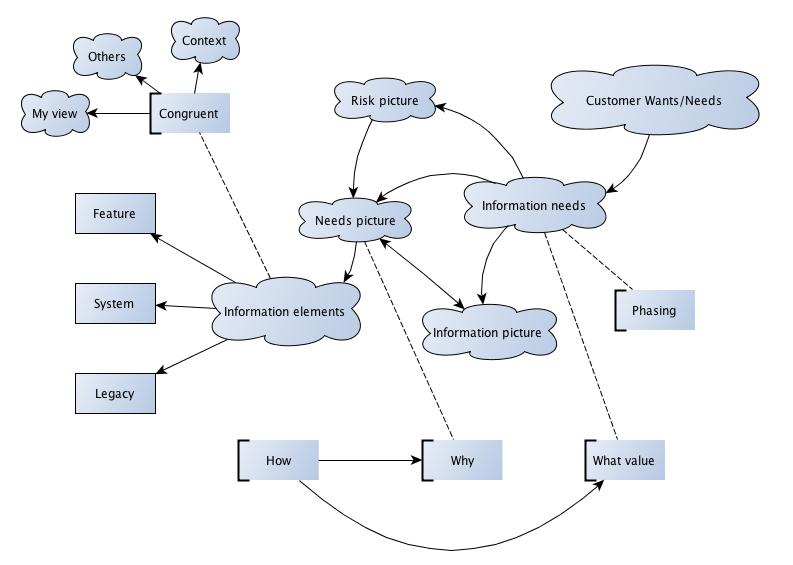
Model #2
When I first presented the above model (#1) and contrasted it with an alternative (#2), in Sept 2012 to a group of my peers, I made it on a large whiteboard with one displayed above the other. I did this to point out that activities and artifacts (model #1) could be mapped into this model.
The second model takes the view of not encapsulating customer requirements, but tries to work with (analyse) what information the customer needs about the product (that they will receive). Part of this can be some traditional requirement labelling, but can also be thinking at a very early stage, “how will I demonstrate or show this to a customer”. This breaks down into a:
Phasing: Sometimes products have dependencies to other product or third-party components and so phasing in time can be needed (from a project perspective).
The needs picture can be decomposed into information elements related to the new feature, the new system and the aspects of the legacy system.
This model also introduces elements of design thinking, see references, to move from the first model (how-> activity + artifact based) to a focus on the why and what value elements to help the needs pictures (of the project and the customer).
Usefulness of this model?
The information model has the purpose of identifying value to the business. We work with the information goals and elements that add value to the business. In this way, we align the development activity (and artifacts) to business goals. Then, maybe we devote less attention on activities (and artifacts) that don’t contribute towards a business goal (ie they add no information that is needed).
From a tester and testing perspective:
An aim with this model is to focus the daily activity wrt answering the question: “What information (and so business value) will my current task add for the customer.**
It forms a chain between daily activities and end goal. This could make reporting about testing (especially status reporting) easier or more accessible to stakeholders. The stakeholders know which thread of business value we are working on and how it contributes to the end goal.
It focusses reporting on information (business) value rather than something that is more abstract, eg test cases.
From a business and organisational perspective:
This is helpful in illustrating the difficulties and complexities of good testing. That requirements are not “things” in isolation, that the value chain in the whole development of the product is should be visible, to illustrate why something is being done or what omitting something might mean. It’s also a useful tool to show why “just test that” isn’t a necessarily simple task.
Background
Communication about testing. Since early 2010 I’ve been looking at different problems (traps) associated with communicating about testing. See references.
Before Let’s Test (May 2012) I had been thinking about communication about testing, especially to stakeholders and other interested parties. During Let’s Test I asked a number of questions related how testers should present information between different layers in the organisation -> ie that models for communication and analysis don’t translate so well between different layers of an organisation (it’s not their purpose, so how do we tackle that?)
In May 2012 I took a course on Value Communication - whilst the focus of it was about communicating key points (especially for execs) I started thinking about information flows in testing.
Work in Progress and Feedback
Notes
[**] Customer, in this model, can be an external or internal customer. It could also be a stakeholder making a release decision.
References
[] Test Reporting to Non-Testers http://www.slideshare.net/YorkyAbroad/test-reporting-tonontesters2010
[] Challenges with Communicating Models http://testers-headache.blogspot.com/2012/07/challenges-with-communicating-models.html
[] Challenges with Communicating Models II http://testers-headache.blogspot.com/2012/07/challenges-with-communicating-models-ii.html
[] Silent Evidence in Testing http://testers-headache.blogspot.com/2012/03/silent-evidence-in-testing.html
[] Taylorism and Testing http://testers-headache.blogspot.com/2011/08/taylorism-and-testing.html
[] Wikipedia: Design Thinking http://en.wikipedia.org/wiki/Design_thinking
The second model takes the view of not encapsulating customer requirements, but tries to work with (analyse) what information the customer needs about the product (that they will receive). Part of this can be some traditional requirement labelling, but can also be thinking at a very early stage, “how will I demonstrate or show this to a customer”. This breaks down into a:
- Needs picture. This might be something close to a traditional requirement description - the items on a delivery checklist to a customer.
- Risk picture. What risks are associated with this product, due to it’s composition, development and it’s context (including legacy system).
- Information picture. What elements are important to tell the story to the customer and how?
Phasing: Sometimes products have dependencies to other product or third-party components and so phasing in time can be needed (from a project perspective).
The needs picture can be decomposed into information elements related to the new feature, the new system and the aspects of the legacy system.
The important thing to bear in mind with these elements is that they must be congruent to add to the bigger picture - that they add value to the element in themselves (eg test of a feature in isolation), add value to the whole (the new system) and their context (to the product that the customer will use - which might be different from a generic system).
This model also introduces elements of design thinking, see references, to move from the first model (how-> activity + artifact based) to a focus on the why and what value elements to help the needs pictures (of the project and the customer).
Usefulness of this model?
The information model has the purpose of identifying value to the business. We work with the information goals and elements that add value to the business. In this way, we align the development activity (and artifacts) to business goals. Then, maybe we devote less attention on activities (and artifacts) that don’t contribute towards a business goal (ie they add no information that is needed).
From a tester and testing perspective:
An aim with this model is to focus the daily activity wrt answering the question: “What information (and so business value) will my current task add for the customer.**
It forms a chain between daily activities and end goal. This could make reporting about testing (especially status reporting) easier or more accessible to stakeholders. The stakeholders know which thread of business value we are working on and how it contributes to the end goal.
It focusses reporting on information (business) value rather than something that is more abstract, eg test cases.
From a business and organisational perspective:
This is helpful in illustrating the difficulties and complexities of good testing. That requirements are not “things” in isolation, that the value chain in the whole development of the product is should be visible, to illustrate why something is being done or what omitting something might mean. It’s also a useful tool to show why “just test that” isn’t a necessarily simple task.
Background
Communication about testing. Since early 2010 I’ve been looking at different problems (traps) associated with communicating about testing. See references.
Before Let’s Test (May 2012) I had been thinking about communication about testing, especially to stakeholders and other interested parties. During Let’s Test I asked a number of questions related how testers should present information between different layers in the organisation -> ie that models for communication and analysis don’t translate so well between different layers of an organisation (it’s not their purpose, so how do we tackle that?)
In May 2012 I took a course on Value Communication - whilst the focus of it was about communicating key points (especially for execs) I started thinking about information flows in testing.
Work in Progress and Feedback
I presented these two models to James Bach as we sat on a train to Stockholm after SWET4. After some discussion about which problems I was trying to look at he commented that I was debugging the information flow. Yes, that was definitely a major aspect, especially when considering the perspectives of the non-testers in this flow, ie how non-testers perceive and interpret information flow to/from testers.
This model is a work in progress, elements in it and its applications. All comments and feedback are very welcome.
Notes
[*] Contrast this activity model with the idea of a test case - which can be thought of as an instantiation of a test idea with a given set of input parameters (which include expectations) - then when the test case is used as an exemplar it becomes a test idea constraint! In this sense the model (of activities and artifacts) constrains the development process. From a testing perspective it constrains the testing.
[**] Customer, in this model, can be an external or internal customer. It could also be a stakeholder making a release decision.
References
[] Test Reporting to Non-Testers http://www.slideshare.net/YorkyAbroad/test-reporting-tonontesters2010
[] Challenges with Communicating Models http://testers-headache.blogspot.com/2012/07/challenges-with-communicating-models.html
[] Challenges with Communicating Models II http://testers-headache.blogspot.com/2012/07/challenges-with-communicating-models-ii.html
[] Silent Evidence in Testing http://testers-headache.blogspot.com/2012/03/silent-evidence-in-testing.html
[] Taylorism and Testing http://testers-headache.blogspot.com/2011/08/taylorism-and-testing.html
[] Wikipedia: Design Thinking http://en.wikipedia.org/wiki/Design_thinking






